MTT Overview
This section gives an overview of the Model Transform Tool (MTT) to put the overall process into context.
It covers the structure and process of MTT and its deployment options.
Tool Structure
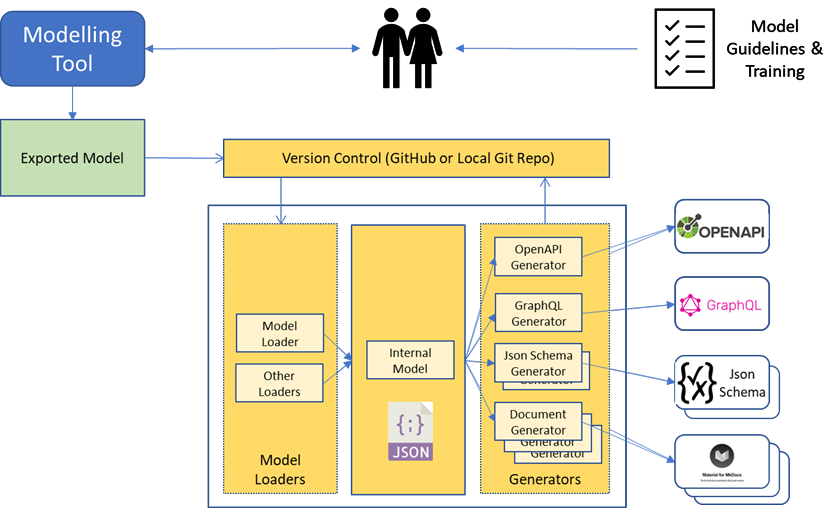
The figure below shows the key components of the MTT:
- Model loaders. The default modelling tool is Sparx EA and the provided loader for its exported XML format. Any modelling tool that can export an information-model can be used and loaded into the MTT internal model, via a custom model loader.
- Internal model. The internal model provides the secret-sauce that enables two key aspects which separate the MTT from traditional code generators:
- Generators can be easily developed, using a range of widely-used programming languages and approaches.
- Supports dependencies between information models, allowing a catalogue of models to be developed and re-used across projects.
- Output generators. Rather than developing models of a particular API or message standard, The MTT works on business information models that are agnostic to the output formats. It is the generators that provide the intelligent mapping from model to specific output. It is this approach that also enables relevant design best-practice and any house standards to be built into the generators.
Deployment
The MTT can be run either:
- Using the web service API Generation MTT, for GitHub based projects (or running the example projects). In this case it can also be integrated with GitHub Actions as part of CD/CI workflow.
- On local infrastructure, as a Docker container. In this case the MTT requires read/write access to project repositories that are mapped as Docker Volumes.
On this page
Need Assistance?
Reach out to the team here